


The Field Of Statistics Is Doomed — Unless It Abandons Testing & Parameter-Based Analysis
The first part of this article also appears at the Broken Science Initiative. Go there to read it, too, and many other good ones by other authors.
We already saw a study from Nate Breznau and others in which a great number of social science researchers were given identical data and asked to answer the same question—and in which the answers to that question were all over the map, with about equals numbers answering one thing and others answering its opposite, all answers with varying strengths of association, and with both sides claiming “statistical significance.”
If “statistical significance”, and statistical modeling practices were objective, as they are claimed to be, then all those researchers should have arrived at the same answer, and the same significance. Since they did not agree, something is wrong with either “significance” or objective modeling, or both.
The answer will be: both. Before we come to that, Breznau’s experiment was repeated, this time in ecology.
The paper is “Same data, different analysts: variation in effect sizes due to analytical decisions in ecology and evolutionary biology” by Elliot Gould and a huge number of other authors, from all around the world, and can be found on the pre-print server EcoEvorxiv.
The work followed the same lines as with Breznau. Some 174 teams, with 246 analysts in total, were given two identical datasets and they were asked “to investigate the answers to prespecified research questions.” One dataset was to “compare sibling number and nestling growth” of blue tits (Cyanistes caeruleus), and the other was “to compare grass cover and tree seedling recruitment” in Eucalyptus.
The analysts arrived at 141 different results for the blue tits and 85 for the Eucalyptus.
For the blue tits (with my emphasis):
For the blue tit analyses, the average effect was convincingly negative, with less growth for nestlings living with more siblings, but there was near continuous variation in effect size from large negative effects to effects near zero, and even effects crossing the traditional threshold of statistical significance in the opposite direction.
Here’s a picture of all the results, which were standardized (that Zr in the figure) across all entries for easy comparison.
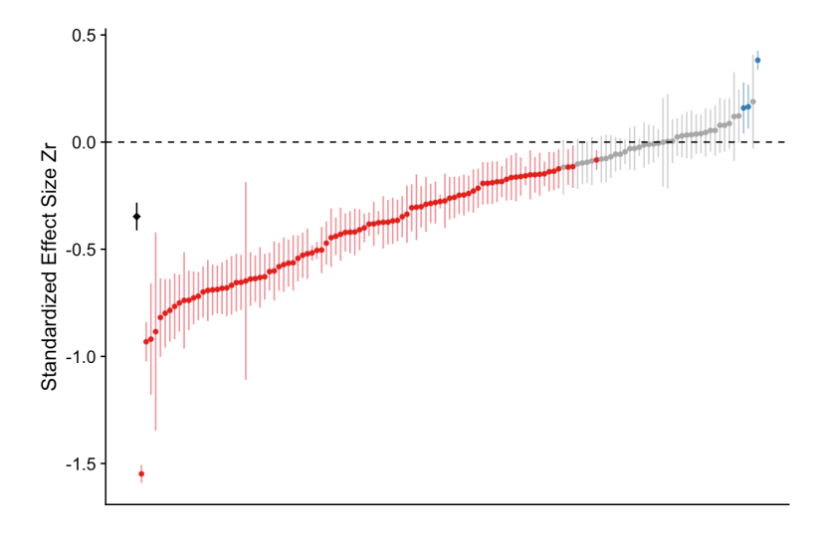
The center of each vertical line is the standardized effect found for each research result, with the vertical lines themselves being a measure of uncertainty of that effect (a “confidence interval”), also given by the researchers. Statistical theory insists most of these vertical lines should overlap on the vertical axis. They do not.
The red dots, as the text indicates, are for negative effects that are “statistically significant”, whereas the blue are for positive, also “significant”.
Now for the Eucalyptus (again my emphasis):
[T]he average relationship between grass cover and Eucalyptus seedling number was only slightly negative and not convincingly different from zero, and most effects ranged from weakly negative to weakly positive, with about a third of effects crossing the traditional threshold of significance in one direction or the other. However, there were also several striking outliers in the Eucalyptus dataset, with effects far from zero.
Here’s the similar picture as above:
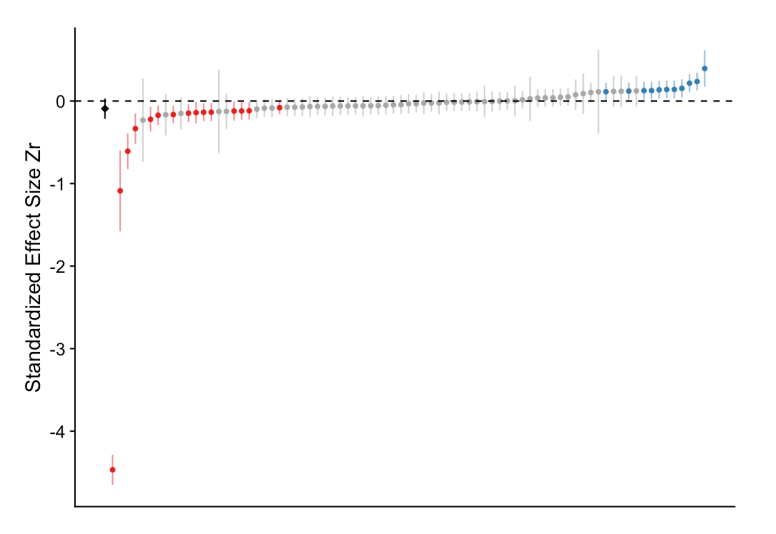
This picture has the same interpretation, but notice the “significant” negative effects are more or less balanced by the “significant” positive effects. With one very large negative effect at the bottom.
If statistical modelling was objective, and if statistical practice and theory worked as advertised, all results should be the same, for both analysis, with only small differences. Yet the differences are many and large, as they were with Breznau; therefore, statistical practice is not objective, and statistical theory is deeply flawed.
There are many niceties in Gould’s paper about how all those analysts carried out their models, with complexities about “fixed” versus “random” effects, “independent” versus “dependent” variables, variable selection and so forth, even out-of-sample predictions, which will be of interest to statisticians. But only to depress them, one hopes, because none of these things made any difference to the outcome that researchers disagreed wildly on simple, well defined analysis questions.
The clever twist with Gould’s paper was that all the analyses were peer reviewed “by at least two other participating analysts; a level of scrutiny consistent with standard pre-publication peer review.” Some analyses came back marked “unpublishable”, other reviewers demanded major or minor revisions, and some said publish-as-is.
Yet the peer-review process, like details about modeling, made no difference either. The disagreements between analysts’ results was the same, regardless of peer-review decision, and regardless of modeling strategies. This is yet more evidence that peer review, as we have claimed many times, is of almost no use and should be abandoned.
If you did not believe Science was Broken, you ought to now. For both Breznau and Gould prove that you must not trust any research that is statistical in nature. This does not mean all research is wrong, but it does mean that there’s an excellent chance that if a study in which you take an interest were to be repeated by different analysts, the results could change, even dramatically. The results could even come back with an opposite conclusion.
What went wrong? Two things, which are the same problem seen from different angles. I’ll provide the technical details in another place. Or those with some background could benefit from reading my Uncertainty, where studies like the one we discussed today above have been anticipated and discussed.
For us, all we have to know is that the standard scientific practice of model building does not guarantee, or even come close to guaranteeing, truth has been discovered. All the analyses handed in above were based on model fitting and hypothesis testing. And these practices are nowhere near sufficient for good science.
To fix this, statistical practice must abandon its old emphasis on model fitting, with its associated hypothesis testing, and move to making—and verifying—predictions made on data never seen or used in any way. This is the way sciences like Engineering work (when they do).
This is the Predictive Way, a prime focus of Broken Science.
Technical Details
I’ve written about this so much that all I can do it repeat myself. But, for the sake of completeness, and to show you why all these current researchers, as with Breznau, thought their models were the right models, I’ll say it again.
All probability is conditional, meaning it changes when you change the assumptions or premises on which you condition it. Probability does not exist. All these statistical models are probability models. They therefore express only uncertainty in some proposition (such as size of nestling growth) conditional on certain assumptions.
Part of those assumptions are on the model form (“normal”, “regression”, etc.), model parameter (the unobservable guts inside models), part are on the “data” input (which after picking and choosing can be anything), on the “variables” (the explicit conditions, the “x”s) and so forth.
Change any of these conditions, and you change the uncertainty in the proposition of interest. (Usually: changed propositions which do not anywhere change the uncertainty in the proposition are deemed irrelevant, a far superior concept to “independence”, if you’ve ever heard of that.)
That’s it. That’s all there is to it. Or, rather, that’s as it should be. That’s the predictive way. That’s the way I advocate in Uncertainty.
What happens instead is great confusion. People forget why they wanted to do statistics—quantifying uncertainty in the propositions of interest—and become beguiled by the math of the models. People forget about uncertainty and instead focus on the guts of the model.
They become fascinated by the parameters. Likely because they believe probability is real, an ontological substance like tree leaves or electricity. They think, therefore, that their conclusions about model parameters are statements about the real world, about Reality itself! Yet this is not so.
Because in the belief of ontological probability, therefore parameters must necessarily also be real, we have things like “hypothesis testing”, an archaic magical practice, not unlike scrying or voodoo. Testing leads to the spectacle of researchers waving their wee Ps in your face, as if they have made a discovery about Reality!
No.
That’s what happened here, with Gould, with Breanau, and with any other collection of studies you can find which use statistics. Only with most collections people don’t it’s happened to them. Yet.
It’s worse that this. Because even if, somehow, hypothesis testing made any sense, researchers still stop short and only release details about the model parameters! This causes mass widespread continuous significant grief. Not the least because people reading research results forget they are reading about parameters (where uncertainty may be small) and think they are reading about Reality (where uncertainty may remain large).
I say this, have said this, yet I am doubted. I wrote a whole book discussing it, and am doubted. But that is exactly why Gould and Breanau exist. This is vindication.
The fix? There is no fix. There is a slight repair we can make, by acknowledging the conditional nature of probability, that it is only epistemological, that at a minimum the only way to trust any statistical model is to observe that it is has made skillful (a technical term) useful (a technical term) predictions of data never before seen or used in any way.
It’s the last that’s a killer. We can just about convince people to think about uncertainty in observables (and not parameters). But that bit about waiting for confirmation of model goodness.
Waiting? Waiting?
That’s too expensive! That limits us! That slows science down!
It does. Slows it way down. For which I can only respond with “You’re welcome.” Do you even remember the last three years of The Science?
Subscribe or donate to support this site and its wholly independent host using credit card click here. Or use the paid subscription at Substack. Cash App: $WilliamMBriggs. For Zelle, use my email: matt@wmbriggs.com, and please include yours so I know who to thank.
With regards to slowing Science down, the classic response from Augustine sums it all up. 'It is better to limp in the right direction than to run in the wrong direction at great speed.'
"The fix? There is no fix."
Or if there is, it is a human one and has nothing to do with statistics. They simply have to be able to admit - to themselves and the world - that they don't understand the things they claimed they understood, a claim their self-esteem was dependent on.
In industrial R&D when you create a model and it doesn't work, you can't say it was "peer reviewed" - the customer just sends the machine back, and someone asks you why your model sucks. I imagine academics regard this process as an annoyance, when in fact subjecting your model to unseen numbers and circumstances is usually the only way work out what is really going on. They are like a sofa musician versus a performing one - much much worse than they think they are.